何谓分支
提交的数据结构
Git 保存的不是文件差异或者变化量,而只是一系列文件快照。在 Git 中提交时,会保存一个提交(commit)对象,该对象包含一个指向暂存内容快照的指针,包含本次提交的作者等相关附属信息,包含零个或多个指向该提交对象的父对象指针:首次提交是没有直接祖先的,普通提交有一个祖先,由两个或多个分支合并产生的提交则有多个祖先。
当使用 git commit 新建一个提交对象前,Git 会先计算每一个子目录的校验和,然后在 Git 仓库中将这些目录保存为树(tree)对象。之后 Git 创建的提交对象,除了包含相关提交信息以外,还包含着指向这个树对象(项目根目录)的指针,如此它就可以在将来需要的时候,重现此次快照的内容了。
单个提交对象在仓库中的数据结构: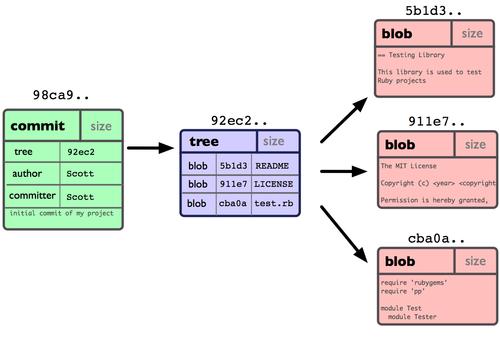
多个提交对象之间的链接关系:
分支简介
Git 中的分支其实就是一个指向 commit 对象的可变指针,master为默认的分支名。在若干次提交后,该指针指向最后一次提交对象的master分支,并且每次提交的时候它都会自动向前移动。
1 | git branch testing #创建分支 |
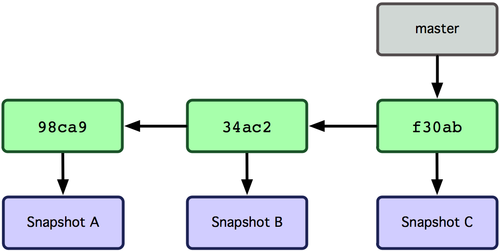
Git 通过一个HEAD指针知道你当前在那个分支工作,运行git branch 命令,仅仅是建立了一个新的分支,但不会自动切换到这个分支中去。

在testing分支提交了一次,然后再切换到master分支:
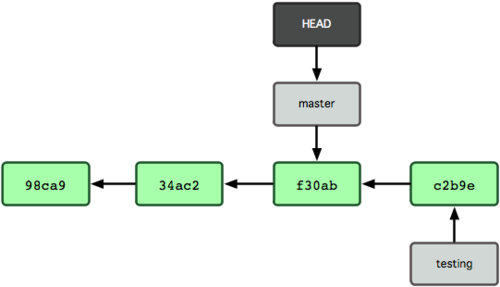
若此时在master分支提交了一次,则会产生分叉:

由于 Git 中的分支实际上仅是一个包含所指对象校验和(40 个字符长度 SHA-1 字串)的文件,所以创建和销毁一个分支就变得非常廉价。说白了,新建一个分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,所以速度很快。
分支的新建与合并
分支的新建
1 | git checkout -b dev #新建并切换到dev分支 |
Git 会把工作目录的内容恢复为检出某分支时它所指向的那个提交对象的快照。它会自动添加、删除和修改文件以确保目录的内容和你当时提交时完全一样。
分支的合并
简单分支的合并

1
2git checkout master
git merge hotfix ##将当前分支与hotfix分支合并
合并后:
这种直接的合并模式是Fast formard模式。由于当前 master 分支所在的提交对象是要并入的 hotfix 分支的直接上游,Git 只需把 master 分支指针直接右移。因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。
之后删除hotfix分支:1
git branch -d hotfix #删除分支
多祖先分支的合并
现在分支情况是这样:
这次 master 与 iss53 分支的合并,并不同于之前 hotfix 的并入方式。由于当前 master 分支所指向的提交对象(C4)并不是 iss53 分支的直接祖先,Git 不得不进行一些额外处理。这里,Git 会用两个分支的末端(C4 和 C5)以及它们的共同祖先(C2)进行一次简单的三方合并计算,为分支合并自动识别出最佳的同源合并点:
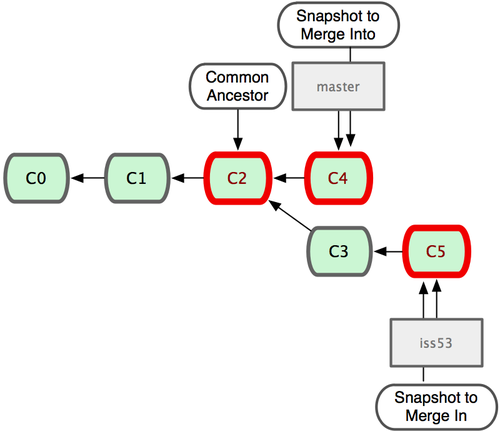
这次,Git 没有简单地把分支指针右移,而是对三方合并后的结果重新做一个新的快照,并自动创建一个指向它的提交对象(C6)。这个提交对象比较特殊,它有两个祖先(C4 和 C5)。

分支合并冲突时的处理
当在不同分支中修改同一文件是,合并时就会发生冲突。这时需要手动解决。任何包含未解决冲突的文件都会以未合并(unmerged)的状态列出。Git 会在有冲突的文件里加入标准的冲突解决标记,可以通过它们来手工定位并解决这些冲突。可以看到此文件包含类似下面这样的部分:1
2
3
4
5
6
7<<<<<<< HEAD:index.html
<div id="footer">contact : email.support@github.com</div>
=======
<div id="footer">
please contact us at support@github.com
</div>
>>>>>>> iss53:index.html
可以看到 ======= 隔开的上半部分,是 HEAD(即 master 分支,在运行 merge 命令时所切换到的分支)中的内容,下半部分是在 iss53 分支中的内容。解决冲突的办法无非是二者选其一或者由你亲自整合到一起。
如果想用一个有图形界面的工具来解决这些问题,不妨运行 git mergetool,它会调用一个可视化的合并工具并引导你解决所有冲突:1
2
3
4
5
6
7
8$ git mergetool
merge tool candidates: kdiff3 tkdiff xxdiff meld gvimdiff opendiff emerge vimdiff
Merging the files: index.html
Normal merge conflict for 'index.html':
{local}: modified
{remote}: modified
Hit return to start merge resolution tool (opendiff):
如果不想用默认的合并工具,你可以在上方”merge tool candidates”里找到可用的合并工具列表,输入想用的工具名。
确认所有冲突都已解决,也就是进入了暂存区,就可以用 git commit 来完成这次合并提交。
分支的管理
1 | git branch #列出当前所有分支 |
利用分支进行开发的工作流程
长期分支
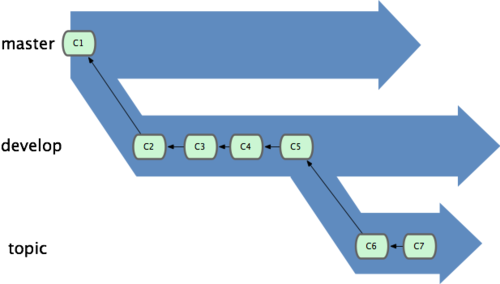
一般 master 分支中保留完全稳定的代码,即已经发布或即将发布的代码;develop 或 next 的平行分支,专门用于后续的开发,不过一旦进入某种稳定状态,便可以把它合并到 master 里;
某些大项目还会有个 proposed(建议)或 pu(proposed updates,建议更新)分支,它包含着那些可能还没有成熟到进入 next 或 master 的内容。
建立不同分支的目的是拥有不同层次的稳定性:当这些分支进入到更稳定的水平时,再把它们合并到更高层分支中去。
特性分支
在任何规模的项目中都可以使用特性(Topic)分支。一个特性分支是指一个短期的,用来实现单一特性或与其相关工作的分支。
远程分支
远程分支(remote branch)是对远程仓库中的分支的索引。它们是一些无法移动的本地分支;只有在 Git 进行网络交互时才会更新。
从github克隆项目,Git 会自动为你将此远程仓库命名为 origin,并下载其中所有的数据,建立一个指向它的 master 分支的指针,在本地命名为 origin/master,但你无法在本地更改其数据。接着,Git 建立一个属于你自己的本地 master 分支,始于 origin 上 master 分支相同的位置,你可以就此开始工作。
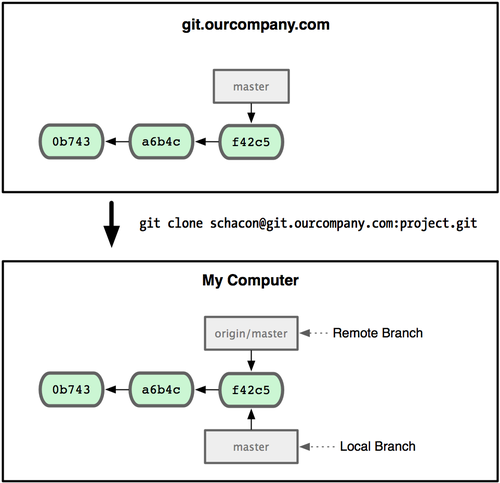
1 | git fetch origin #同步远程服务器上的数据到本地 |
该命令首先找到 origin 是哪个服务器,从上面获取你尚未拥有的数据,更新你本地的数据库,然后把 origin/master 的指针移到它最新的位置上。

若有多个远程分支,可以用 git remote add 添加为当前项目的远程分支之一。
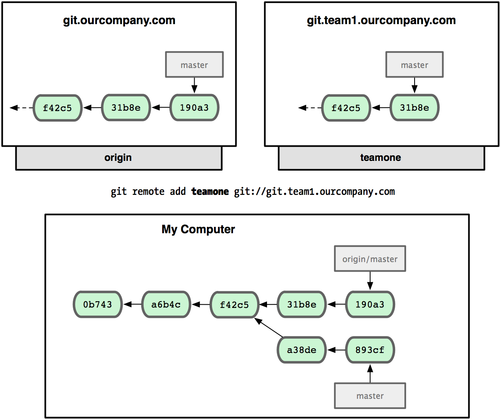
现在,可以使用 git fetch teamone 来获取小组服务器上你还没有的数据了。由于当前该服务器上的内容是你 origin 服务器上的子集,Git 不会下载任何数据,而只是简单地创建一个名为 teamone/master 的远程分支,指向 teamone 服务器上 master 分支所在的提交对象 31b8e:

推送本地分支
1 | git push (远程仓库名) (分支名) |
Git 自动把 serverfix 分支名扩展为 refs/heads/serverfix:refs/heads/serverfix,意为“取出我在本地的 serverfix 分支,推送到远程仓库的 serverfix 分支中去”。
也可以运行 git push origin serverfix:serverfix 来实现相同的效果,它的意思是“上传我本地的 serverfix 分支到远程仓库中去,仍旧称它为 serverfix 分支”。
通过此语法,可以把本地分支推送到某个命名不同的远程分支:若想把远程分支叫作 awesomebranch,可以用 git push origin serverfix:awesomebranch 来推送数据。
接下来协同作者使用git fetch 下载远程分支。注意,在 fetch 操作下载好新的远程分支之后,仍然无法在本地编辑该远程仓库中的分支。在本例中,你不会有一个新的 serverfix 分支,有的只是一个你无法移动的 origin/serverfix 指针。
如果要把该远程分支的内容合并到当前分支,可以运行 git merge origin/serverfix。如果想要一份自己的 serverfix 来开发,可以在远程分支的基础上分化出一个新的分支来:1
2git checkout -b serverfix origin/serverfix
git checkout -b sf origin/serverfix #设定不同的本地分支名
跟踪远程分支
从远程分支 checkout 出来的本地分支,称为 跟踪分支 (tracking branch)。跟踪分支是一种和某个远程分支有直接联系的本地分支。在跟踪分支里输入 git push,Git 会自行推断应该向哪个服务器的哪个分支推送数据。同样,在这些分支里运行 git pull 会获取所有远程索引,并把它们的数据都合并到本地分支中来。
在克隆仓库时,Git 通常会自动创建一个名为 master 的分支来跟踪 origin/master。
1 | $ git checkout --track origin/serverfix |
删除远程分支
1 | git push [远程名] :[分支名] |
1 | $ git push origin :serverfix |
git push [远程名] [本地分支]:[远程分支] ,如果省略 [本地分支],那就等于是在说 “在这里提取空白然后把它变成[远程分支]”,也就是删除远程分支了。
分支的衍合
基本衍合操作
把一个分支中的修改整合到另一个分支的办法有两种:merge 和 rebase(衍合)。

把在 C3 里产生的变化补丁在 C4 的基础上重新打一遍。在 Git 里,这种操作叫做衍合(rebase)。有了 rebase 命令,就可以把在一个分支里提交的改变移到另一个分支里重放一遍。1
2
3
4$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command
它的原理是回到两个分支最近的共同祖先,根据当前分支(也就是要进行衍合的分支 experiment)后续的历次提交对象(这里只有一个 C3),生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象(C4)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象(C3’),从而改写 experiment 的提交历史,使它成为 master 分支的直接下游。
回到 master 分支,进行一次快进合并:
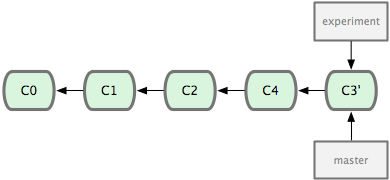
衍合能产生一个更为整洁的提交历史。如果视察一个衍合过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。
一般使用衍合的目的是想要得到一个能在远程分支上干净应用的补丁。注意,合并结果中最后一次提交所指向的快照,无论是通过衍合,还是三方合并,都会得到相同的快照内容,只不过提交历史不同罢了。衍合是按照每行的修改次序重演一遍修改,而合并是把最终结果合在一起。
有趣的衍合
对于下面的工作分支图:
如果想要一次性把 client 分支合并到 master 分支而不通过 server 分支,这是可以通过衍合:1
$ git rebase --onto master server client
使用 --onto选项指定新的基底分支 master。这段命令的大致意思就是:取出 client 分支,找出 client 分支和 server 分支的共同祖先之后的变化,然后把它们在 master 上重演一遍。
合并之后,分支图如下图:
之后git merge client:
若此时把 server 分支的变化也包含进来,可以直接把 server 衍合到 master 中,而不用手工切换到server分支后再衍合——git rebase [主分支] [特性分支] 命令会先取出特性分支 server,然后在主分支 master 上重演。
之后再merge然后删掉特性分支就行了。
衍合的风险
使用衍合要遵守一条准则:
一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行衍合操作。
在进行衍合的时候,实际上抛弃了一些现存的提交对象而创造了一些类似但不同的新的提交对象。如果你把原来分支中的提交对象发布出去,并且其他人更新下载后在其基础上开展工作,而稍后你又用
git rebase抛弃这些提交对象,把新的重演后的提交对象发布出去的话,你的合作者就不得不重新合并他们的工作,这样当你再次从他们那里获取内容时,提交历史就会变得一团糟。
假如在一个人中央服务器克隆然后在它的基础上研发:
现在,某人在 C1 的基础上做了些改变,并合并他自己的分支得到结果 C6,推送到中央服务器。当你抓取并合并这些数据到你本地的开发分支中后,会得到合并结果 C7,历史提交会变成下图:
接下来,那个推送 C6 上来的人决定用衍合取代之前的合并操作;继而又用 git push --force 覆盖了服务器上的历史,得到 C4’。而之后当你再从服务器上下载最新提交后,会得到:
此时下载更新后需要合并,然而此时衍合产生的C4的SHA-1校验码和之前的C4完全不同,所以 Git 会把它们当作新的提交对象处理,而实际上此刻你的提交历史 C7 中早已经包含了 C4 的修改内容,于是合并操作会把 C7 和 C4’ 合并为 C8。
而当你推送C8时,由于你的提交历史里就会同时包含 C4 和 C4’,两者有着不同的 SHA-1 校验值,如果用 git log 查看历史,会看到两个提交拥有相同的作者日期与说明,令人费解。而更糟的是,当你把这样的历史推送到服务器后,会再次把这些衍合后的提交引入到中央服务器,进一步困扰其他人。
如果把衍合当成一种在推送之前清理提交历史的手段,而且仅仅衍合那些尚未公开的提交对象,就没问题。如果衍合那些已经公开的提交对象,并且已经有人基于这些提交对象开展了后续开发工作的话,就会出现叫人沮丧的麻烦。