语义分割一直是计算机视觉领域非常重要的研究方向,随着深度学习的发展,语义分割任务也得到了十足的进步, 本文从论文出发综述语义分割方法.
语义分割是指像素级的图像理解,即对图像中的每个像素标注所属的类别。示例图如下所示:

左图:输入图像;右图:图像的语义分割结果(源于:PASCAL VOC2011 Example SegmentationsPASCAL VOC2011 Example Segmentations)
除了识别图中的摩托车和车手外,我们还要标注每个目标的边界。因此,不同于图像分割,语义分割需要模型能够进行密集的像素级分类。
其中,VOC2012 和 MSCOCO 是语义分割领域重要的数据集。
语义分割方法
在深度学习广泛应用于计算机视觉领域之前,人们一般使用 TextonForest 和 Random Forest based classifiers 的方法进行语义分割。CNN(Convolutional Neural Network,卷积神经网络)不仅有助于图像识别,在图像的语义分割问题中同样取得了成功。
深度学习方法中常见的一种语义分割方法是 图像块分类(patch classification),即利用像素周围的图像块对每一个像素进行分类。的原因是网络模型通常包含全连接层(fully connect layer),而且要求固定大小的图像输入。
2014 年,加州大学伯克利分校的 Long 等人提出 全卷积网络(Fully Convolutional Networks,FCN),使得卷积神经网络不需要全连接层就可以实现密集的像素级分类,从而成为当前非常流行的像素级分类 CNN 架构。由于不需要全连接层,所以可以对任意大小的图像进行语义分割,而且比传统方法要快上很多。之后,语义分割领域几乎所有的先进方法都是基于该模型进行扩展的。
除了全连接层,池化层(pooling layer)是 CNN 语义分割中的另一个主要问题。CNN 中池化层能够扩大感受野,丢弃位置信息(where information)从而聚合上下文信息。但是语义分割要求类别图完全贴合(exact alignment),因此需要保留位置信息。本文将介绍两种不同的分类架构解决这个问题。
一种是 编码器-解码器(encoder-decoder) 架构。编码器通过池化层逐渐减少空间维度,解码器则逐渐恢复物体的细节和空间维度。编码器到解码器之间通常存在快捷连接(shortcut connections),从而更好地恢复物体的细节信息。U-Net 是这类架构中最常用的模型之一。
U-Net: 编码器-解码器架构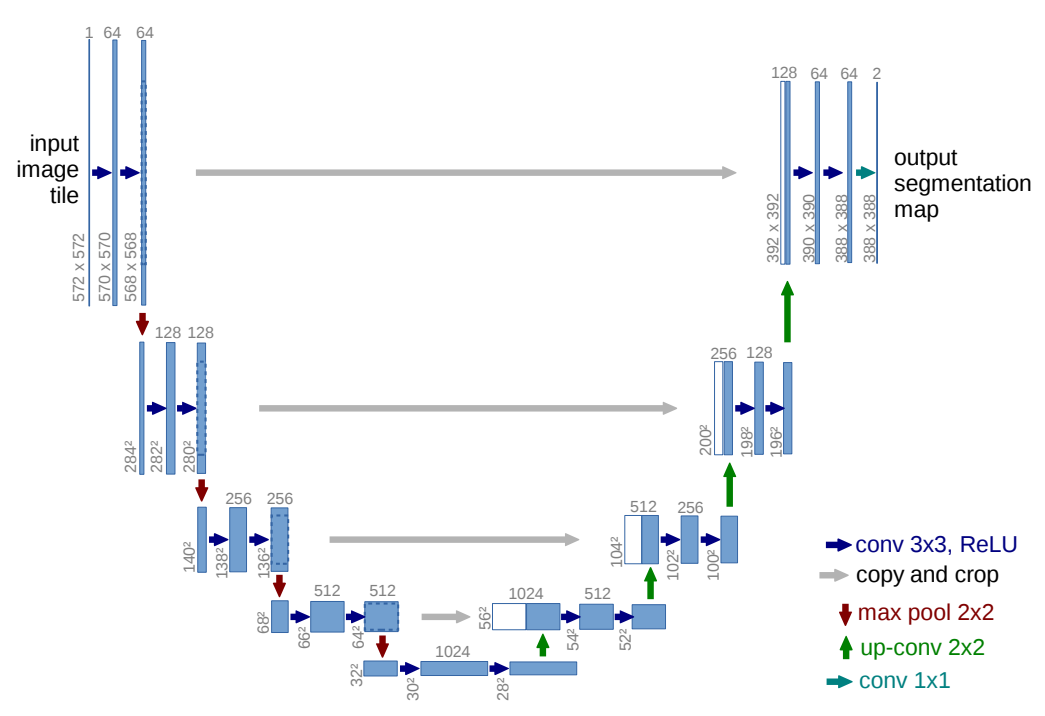
第二种这类架构使用 空洞/带孔卷积(dilated/atrous convolutions) 结构,从而去除池化层。
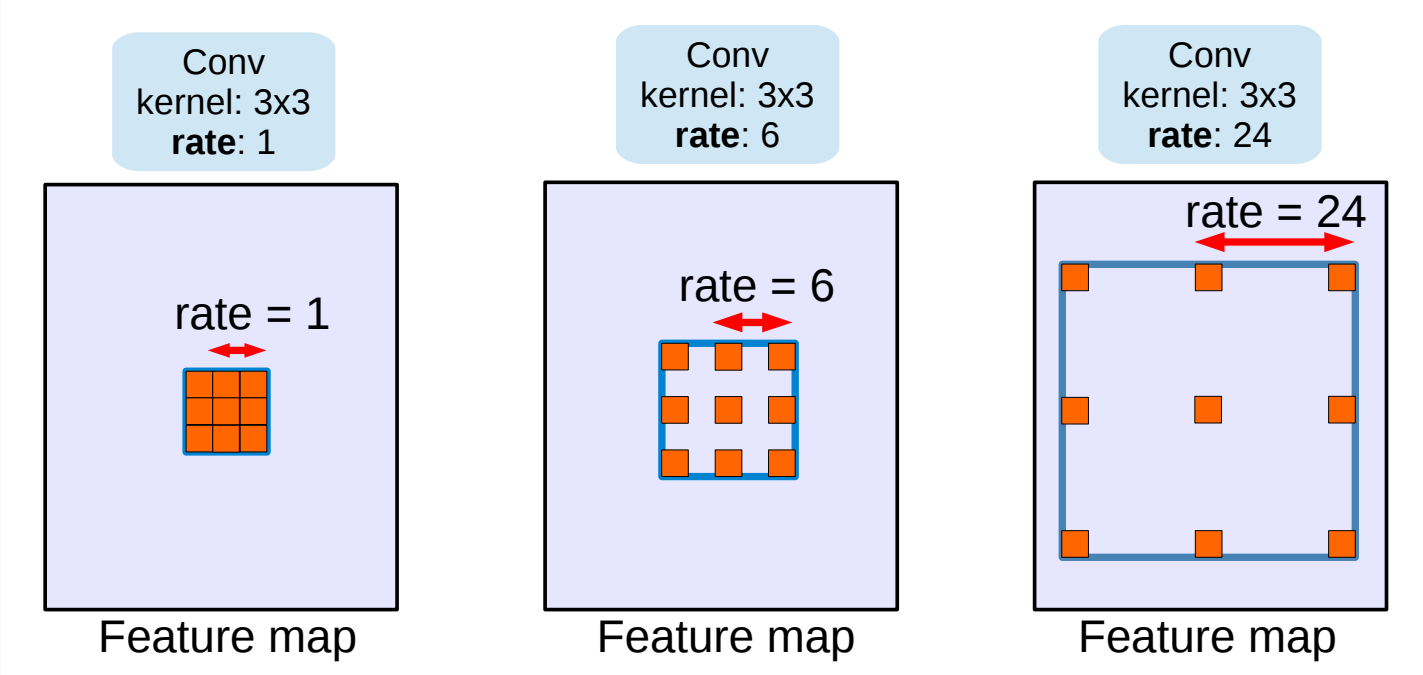
Dilated/atrous卷积结构, 当rate=1时退化为普通的卷积结构.
条件随机场(Conditional Random Field,CRF) 后处理操作通常用于进一步改善分割的效果。CRFs 是一种基于底层图像的像素强度进行“平滑”分割(‘smooth’ segmentation)的图模型,其工作原理是相似强度的像素更可能标记为同一类别。CRFs 一般能够提升 1-2% 的精度。
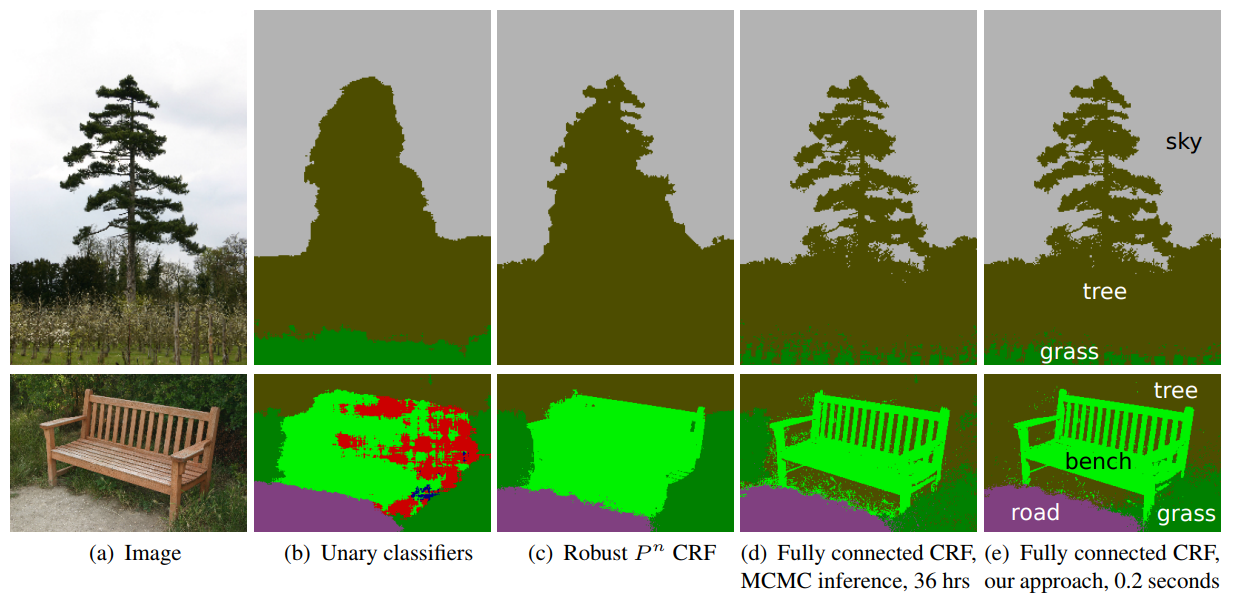
CRF示意图。(b)一元分类结合CRF;(c, d, e)是CRF的变体,其中(e)是广泛使用的一种CRF。
接下来本文将概述从 FCN 以来一些具有代表性的图像语义分割的论文及其对应的架构,这些架构使用 VOC2012 评估服务器 进行基准测试。
FCN
Fully Convolutional Networks for Semantic Segmentation
Submitted on 14 Nov 2014
这篇论文的主要思路是把 CNN 改成 FCN, 输入一幅图像后直接在输出端得到 dense prediction,也就是每个像素所属的 class,从而得到一个端到端的方法来实现图像的语义分割。
假设我们已经有了一个 CNN 模型, 首先要把 CNN 的全连接层看成是卷积层,卷积模板大小就是输入的特征 map 的大小,也就是说把全连接网络看成是对整张输入 map 做卷积。全连接层分别有 4096 个 66 的卷积核,4096 个 11 的卷积核,1000个1*1 的卷积核,如下图:
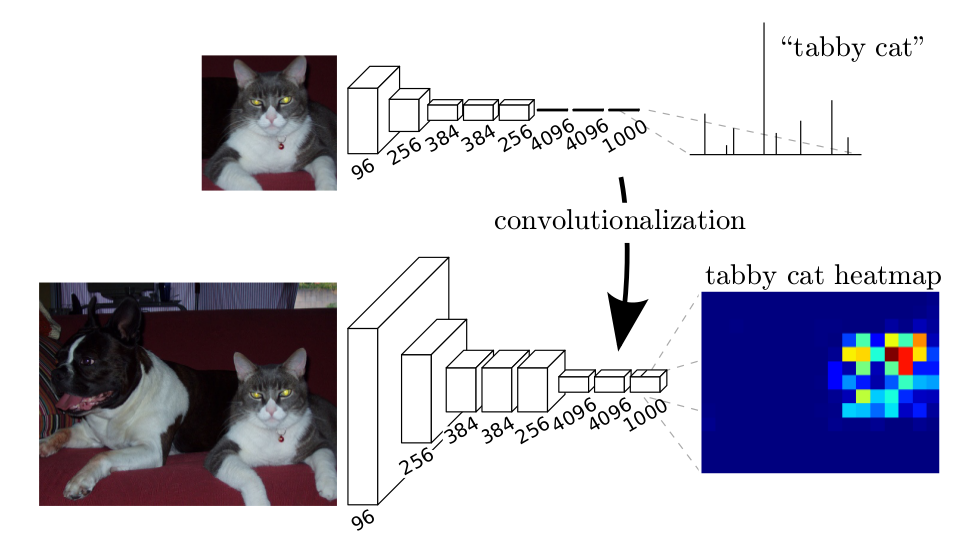
接下来就要对这 1000 个 11 的输出,做 upsampling,得到 1000 个原图大小(如 3232 )的输出,这些输出合并后,得到上图所示的 heatmap 。
这样做的好处是,能够很好的利用已经训练好的网络,不用像已有的方法那样,从头到尾训练,只需要微调即可,训练高效。
反卷积
论文通过 upsampling 得到 dense prediction,文中提及到 3 种方案:
- shift-and-stitch: 设原图与 FCN 所得输出图之间的降采样因子是 f,那么对于原图的每个 ff 的区域(不重叠), 把这个 ff 区域对应的 output 作为此时区域中心点像素对应的 output,这样就对每个 f*f 的区域得到了 $f^2$ 个 output,也就是每个像素都能对应一个 output,所以成为了 dense prediction;
- filter rarefaction:就是放大 CNN 网络中的 subsampling 层的 filter 的尺寸,得到新的 filter. 公式如下, 其中 s 是 subsampling 的滑动步长,这个新 filter 的滑动步长要设为 1,这样的话,subsampling 就没有缩小图像尺寸,最后可以得到 dense prediction;
- upsampling 的操作可以看成是反卷积(deconvolutional), 卷积运算的参数和CNN的参数一样是在训练FCN模型的过程中通过bp算法学习得到.
作者没有采用前两种方法, 而使用了最后一种反卷积的方法. 对于第一种方法, 虽然 receptive fileds 没有变小,但是由于原图被划分成 f*f 的区域输入网络,使得 filters 无法感受更精细的信息; 对于第二种方法, 下采样的功能被减弱,使得更细节的信息能被 filter 看到,但是 receptive fileds 会相对变小,可能会损失全局信息,且会对卷积层引入更多运算。
反卷积示意图: 蓝色是反卷积层的input,绿色是反卷积层的output
kernel size = 3, stride = 1 的反卷积,input 是 2×2, output 是 4×4:
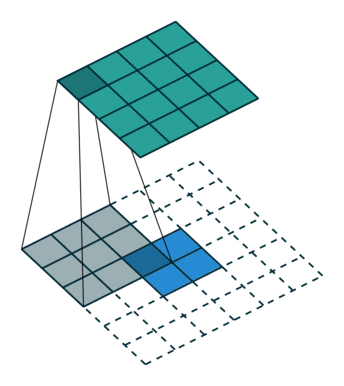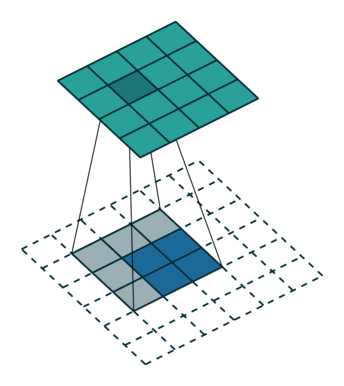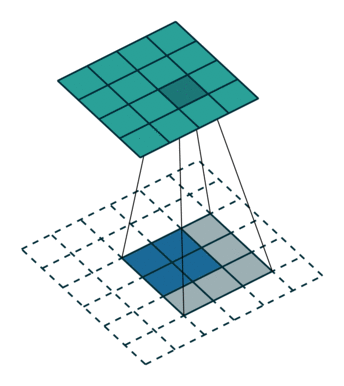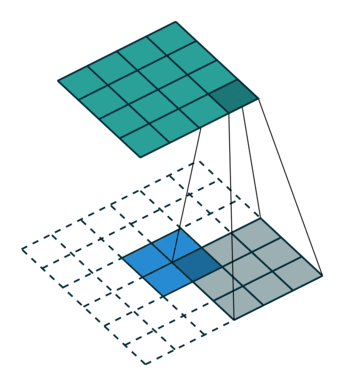
kernel size = 3, stride = 2 的反卷积,input 是 3×3, output 是 5×5:
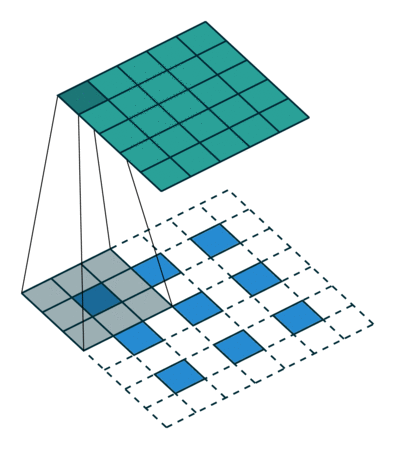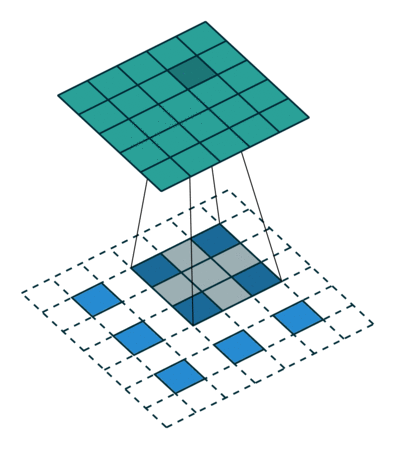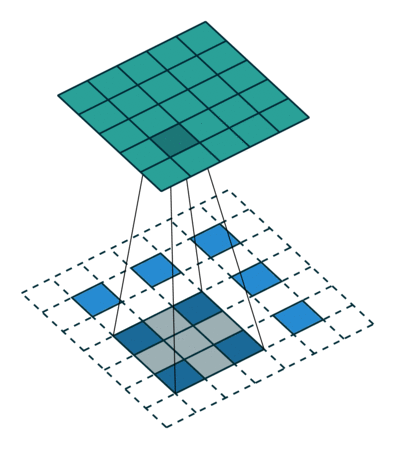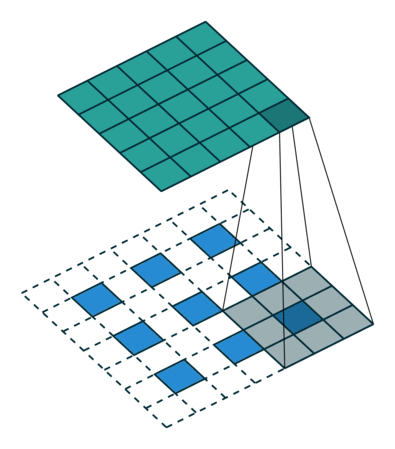
解卷积层也被称作:上卷积(upconvolution),完全卷积(full convolution),转置卷积(transposed convolution)或者微步卷积(fractionally-strided convolution)
fusion prediction
由于池化操作造成的信息损失,上采样(即使采用解卷积操作)只能生成粗略的分割结果图。因此,论文从高分辨率的特征图中引入跳跃连接(shortcut/skip connection)操作改善上采样的精细程度:
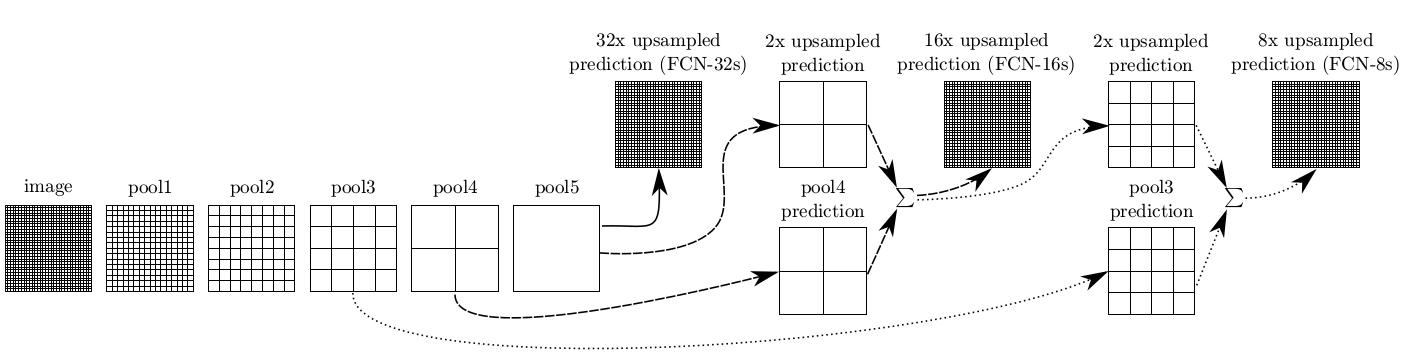
实验表明,这样的分割结果更细致更准确。在逐层fusion的过程中,做到第三行再往下,结果又会变差,所以作者做到这里就停了。可以看到如上三行的对应的结果:
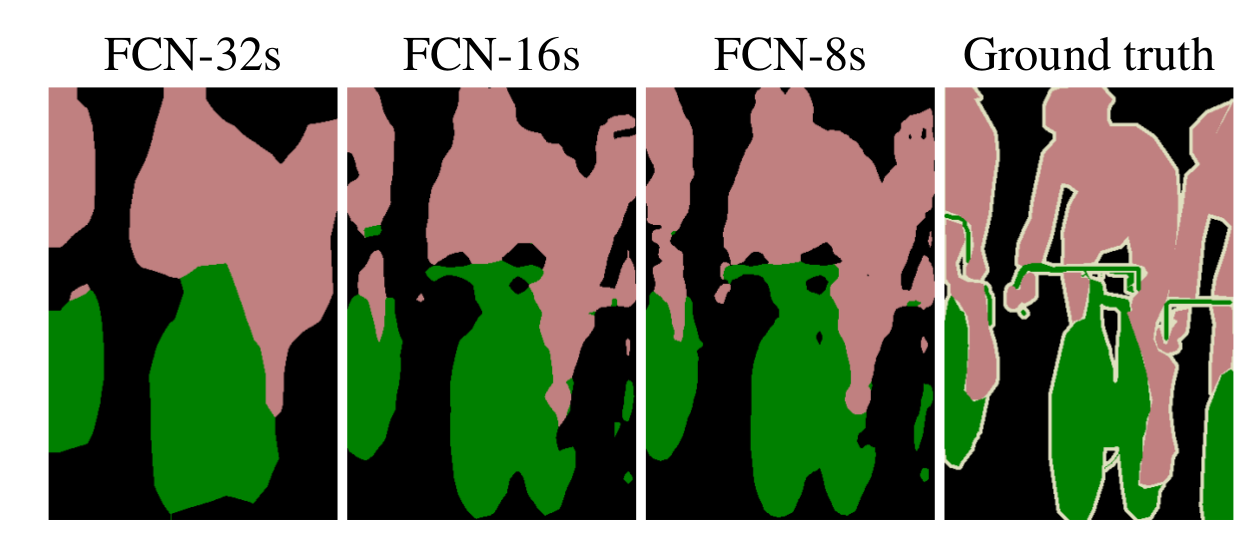
总结
- 推广端到端卷积网络在语义分割领域中的应用
- 修改ImageNet预训练模型并应用于图像语义分割
- 采用解卷积层(deconvolutional layer)实现上采样
- 引入跳跃连接(skip connections)改善上采样的粒度(coarseness)
FCN 对于语义分割领域来说贡献巨大,但是它容易丢失较小的目标, 当前的方法已经取得了很大的提升。
SegNet
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Submitted on 2 Nov 2015
尽管 FCN 网络中使用了解卷积层和少量跳跃连接,但输出的分割图比较粗略,因此本文引入更多的跳跃连接。但是,SegNet 并没有复制 FCN 中的编码器特征,取而代之的是复制最大池化索引。因此,SegNet 相对于 FCN 来说更节省内存。
SegNet 网络架构如下图所示: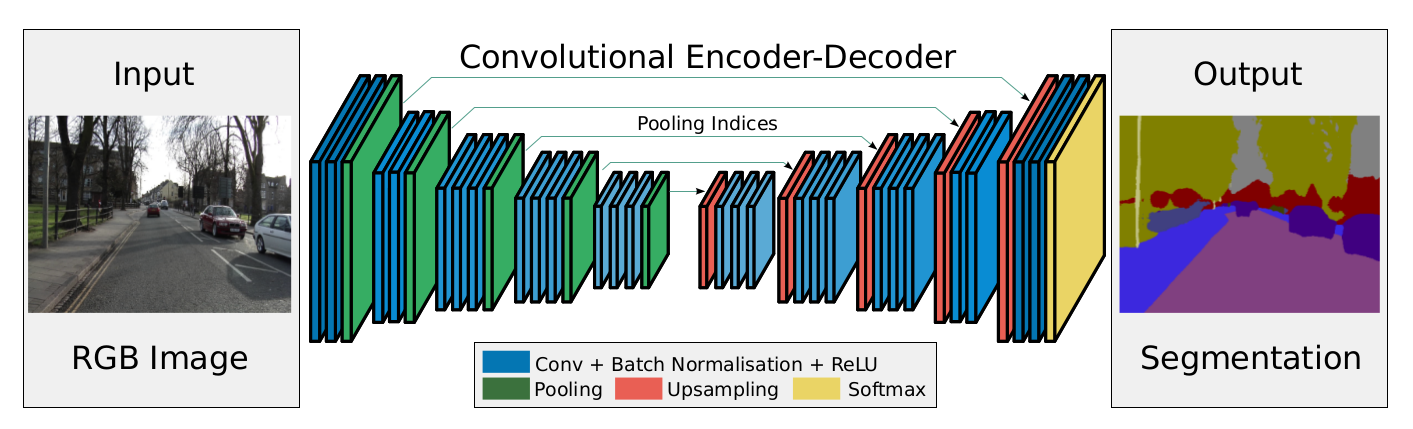
SegNet 有三个部分构成:一个 encoder network,一个对应的 decoder network,最后一个像素级别的分类层.
编码器部分使用的是 VGG16 的前 13 层卷积网络,可以尝试使用 Imagenet 上的预训练. 还可以丢弃完全连接的层,有利于在最深的编码器输出处保留较高分辨率的特征图, 与其他最近的架构 FCN 和 DeconvNet 相比,这也减少了SegNet编码器网络中的参数数量. 每个编码器由卷积层、批归一化层、RELU 组成,之后,执行具有 2×2 窗口和步幅 2(非重叠窗口)的最大池化,输出结果相当于系数为 2 的下采样.最大池化用于实现输入图像中小空间位移的平移不变性,子采样导致特征图中每个像素的大输入图像上下文(空间窗口). 由于最大池化和子采样的叠加,导致边界细节损失增大,因此必须在编码特征图中在 sub-sampling 之前捕获和储存边界信息. 为了高效,论文只储存了最大池化索引(max-pooling indices). 对于每个 2×2 池化窗口,这可以使用 2 位来完成,因此与浮动精度的记忆特征图相比,存储效率更高.
解码器网络中的解码器使用来自对应的编码器特征图存储的最大池化索引来上采样至其输入特征图. 此步骤产生稀疏特征图, 然后将这些特征图与可训练的解码器滤波器组卷积以产生密集的特征图. 注意,最后一个解码器产生一个多通道的特征图,而不是3通道的(RGB). 之后特征图输入给一个 softmax 分类器. 这个 softmax 独立地分类每个像素. softmax 分类器的输出是 K 通道图像的概率,其中 K 是类的数量, 预测的分割对应于在每个像素处具有最大概率的类.
使用最大池化索引的解码器示意图: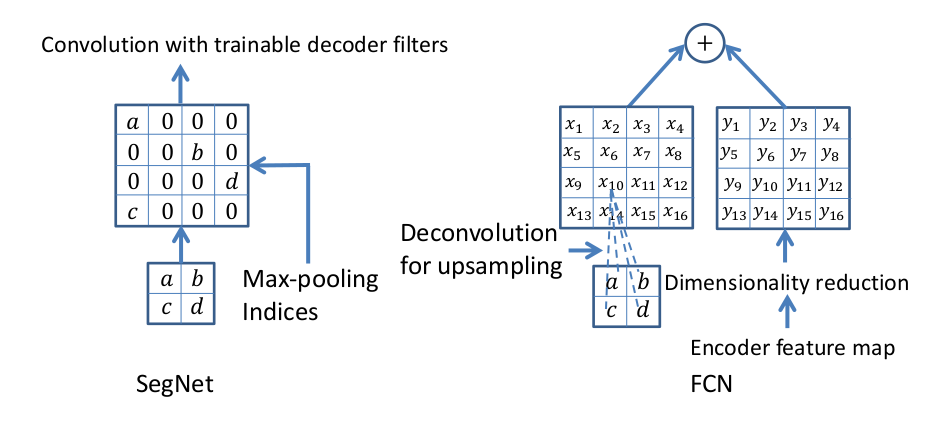
SegNet 部分分割结果如下:
总结
- FNC 和 SegNet 都是最早提出编码器-解码器结构的网络
- 分割的精度略好于 FCN, 总体效率也比 FCN 略高
- SegNet 架构的基准测试分数一般,不建议继续使用
Dilated Convolutions
Multi-Scale Context Aggregation by Dilated Convolutions
Submitted on 23 Nov 2015
在基于 FCN 思想的语义分割问题中,输出图像的 size 要和输入图像的 size 一致。但是 FCN 中由于有若干 stride>1 的池化层,所以越到较高的网络层,单位像素中包含的原始图像的信息就越多,也就是感受野越大,但这是以通过池化降低分辨率、损失原始图像中的信息作为代价而得来的。由于 pooling 层的存在,后面层的 feature map 的 size 会越来越小,但由于需要计算 loss 等原因,最后输出图像的 size 要和输入图像的 size 保持一致,所以在 FCN 中的后段网络层中,必须对 feature map 进行上采样操作,将缩小的 feature map 再还原到原始尺寸,在这个过程中,不可能将在池化过程中丢失的信息完全还原回来,这样就造成了信息的丢失、语义分割的精度降低。
若不加 pooling 层,在较小的卷积核尺寸的前提下,感受野会很小;但如果为了增大感受野,在中段的网络层中使用 size 较大的卷积核,计算量又会暴增,内存扛不住, 因为中段的 channel 一般会非常大,比如 1024、2018,跟最开始 rgb 图像的 3 个 channel 比起来,增大了几百倍。
这种情况下, 作者提出空洞卷积层,其工作原理如下:
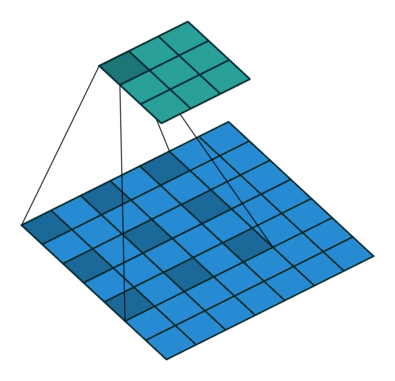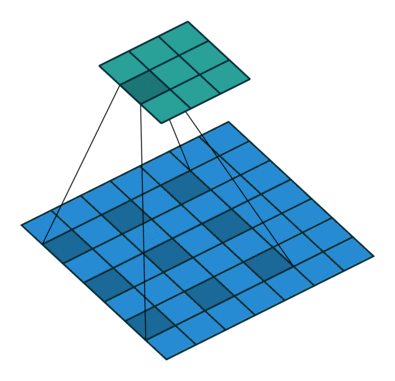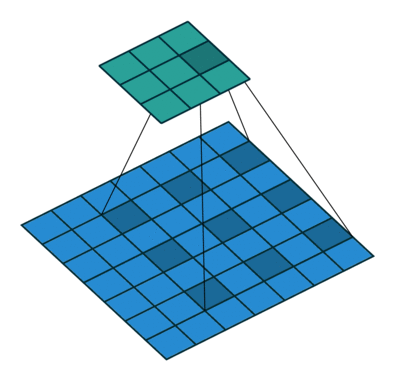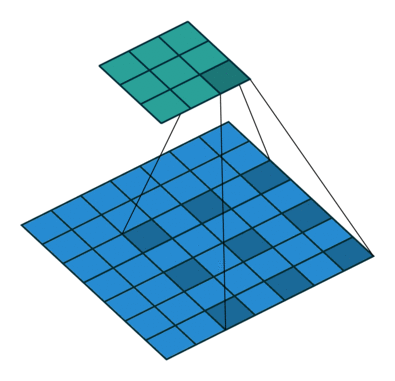
Dilated Convolution 想法很粗暴,既然池化的下采样操作会带来信息损失,那么就把池化层去掉。但是池化层去掉随之带来的是网络各层的感受野变小,这样会降低整个模型的预测精度。Dilated convolution 的主要贡献就是,如何在去掉池化下采样操作的同时,而不降低网络的感受野。
Dilated Convolution
定义离散函数:$\mathbf{F}: \mathbb{Z}^2 \rightarrow \mathbb{R}$, 假设 $\Omega_r = [−r,r]^2 \bigcap \mathbb{Z}^2,k: \Omega_r \rightarrow \mathbb{R}$ 是大小为 $(2r+1)^2$ 的离散 filter. 则离散卷积操作 ∗ 的定义为:
其一般化形式为:
其中 $l$ 为 dilation 因子,$∗_l$ 为 dilation convolution. 当 $l=1$ 时,即为普通的离散卷积操作 ∗.
基于 Dilation Convolution 的网络支持接受野的指数增长,不丢失分辨率信息.
记 $F_0,F_1,…,F_{n−1}: \mathbb{Z}^2 \rightarrow \mathbb{R}$ 为离散函数, $k_0,k_1,…, k_{n−2}: \Omega_1 \rightarrow \mathbb{R}$ 是离散的 3×3 fliters, 采用指数增长 dilation 的 filters后,
定义 $F_{i+1}$ 中的元素 p 的接受野为:$F_0$ 中可以改变 $F_{i+1}(p)$ 值的元素集. $F_{i+1}$ 中 p 的接受野的大小即为这些元素集的数目.
显而易见,$F_{i+1}$ 中各元素的接受野大小为 $(2^{i+2}−1)×(2^{i+2}−1)$. 接受野是指数增长大小的平方.
如下图.
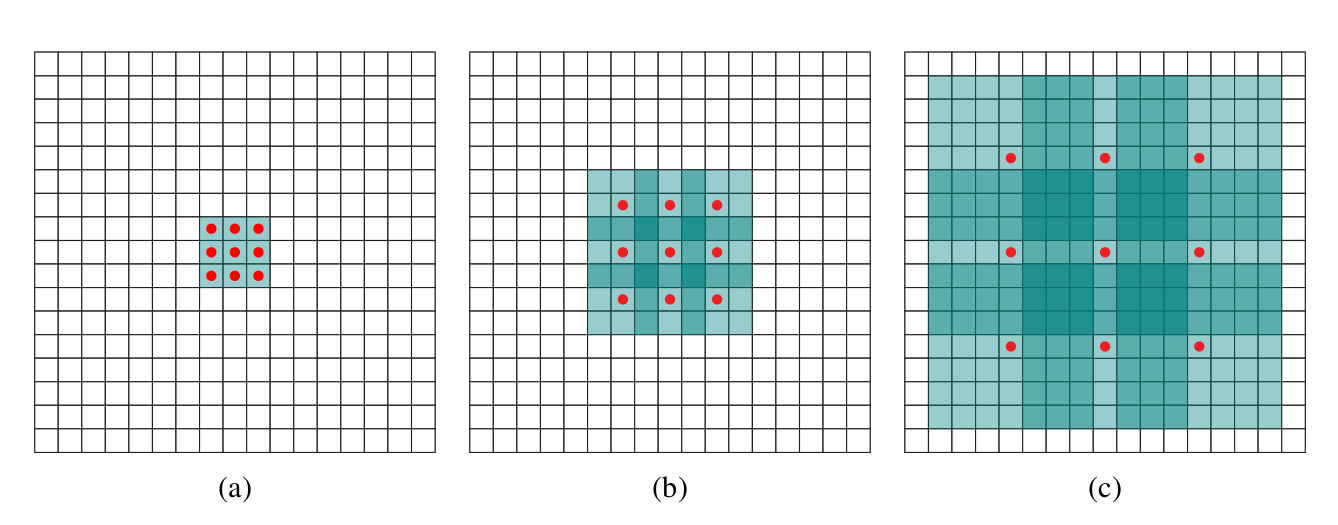
以 $3 \times 3$ 的卷积核为例,传统卷积核在做卷积操作时,是将卷积核与输入张量中“连续”的 $3 \times 3$ 的 patch 逐点相乘再求和(如上图 a,红色圆点为卷积核对应的输入“像素”,绿色为其在原输入中的感知野)。而 dilated convolution 中的卷积核则是将输入张量的 $3\times 3$ patch 隔一定的像素进行卷积运算。如上图 b 所示,在去掉一层池化层后,需要在去掉的池化层后将传统卷积层换做一个 “dilation=2” 的 dilated convolution 层,此时卷积核将输入张量每隔一个“像素”的位置作为输入 patch 进行卷积计算,可以发现这时对应到原输入的感知野已经扩大(dilate)为 $7 \times 7$;同理,如果再去掉一个池化层,就要将其之后的卷积层换成 “dilation=4” 的 dilated convolution 层,如上图 c 所示。这样一来,即使去掉池化层也能保证网络的感受野,从而确保图像语义分割的精度。
Dilated Convolution 能够不减少空间维度的前提下,使感受野呈现指数级增长。
Multi-scale Context Aggreation
上述模块在论文中称作前端模块(frontend module),使用上述模块之后,无需增加参数即可实现密集的像素级类别预测。另一个模块在论文中称作上下文模块(context module),使用前端模块的输出作为输入单独训练。该模块由多个不同扩张程度(dilation)的 dilated convolution 级联而成,因此能够聚合不同尺度的上下文信息,从而改善前端模块输出的预测结果。
context module 的结构如下:
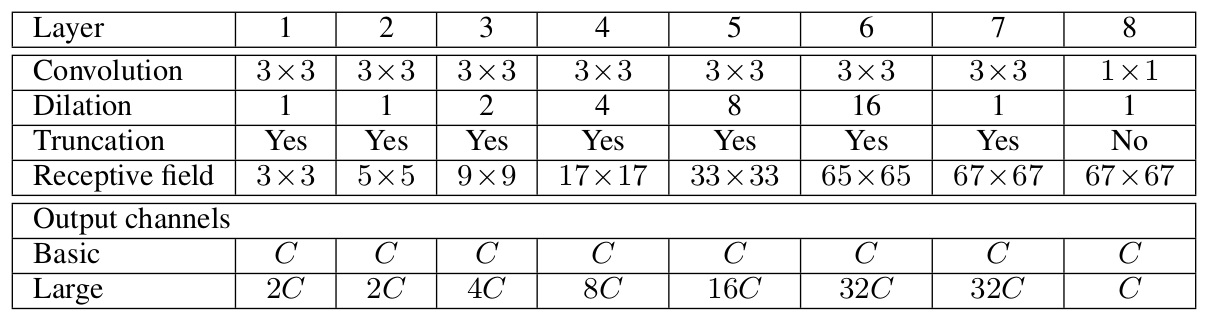
context 模块的基本形式中,各层具有 C 个 channels. 尽管特征图没有归一化,模块内也没有定义 loss,但各层的表示是相同的,可以直接用于获得 dense per-class prediction. 直观上是可以增加特征图的准确度的.
基本的 context 模块有 7 层,各层采用具有不同的 dilation 因子的 3×3 卷积. 各卷积操作后跟着一个逐元素截断 (pointwise truncation) 操作:max(⋅,0). 最终的输出是采用 1×1×C 的卷积操作得到的.
总结
- 采用空洞卷积(dilated convolution)作为能够实现像素级预测的卷积层
- 提出“背景模块”(context module),用于空洞卷积的多尺度聚合
- 预测分割图的大小是原始图大小的 1/8,几乎所有的方法都是这样,一般通过插值得到最终的分割结果
DeepLab (v1 & v2)
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Submitted on 22 Dec 2014
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Submitted on 2 Jun 2016
论文认为之前基于 FCN 的语义分割方法有如下几个问题:
- 池化层和下采样使特征图的分辨率降低
- 多尺度物体检测
- 深度卷积神经网络的不变性造成的定位精度减少
针对以上三个问题, DeepLab 分别提出了三个解决方案。
- 针对分辨率降低的问题,DeepLab 提出使用 Atrous convolution, 这其实和上一个 dilated convolution 一样
- 传统方法是把 image 强行转成相同尺寸,这样会导致某些特征扭曲或者消失。作者的想法是借用空间金字塔池化 (spatial pyramid pooling)的思想,使用了 ASPP (atrous SPP) 来解决这个问题
- 解决 DCNN invariance 可以选择挑过一些层,不过这里作者选择了全连接的 CRF 改善定位精度
所以论文解决方案的整体流程如下:
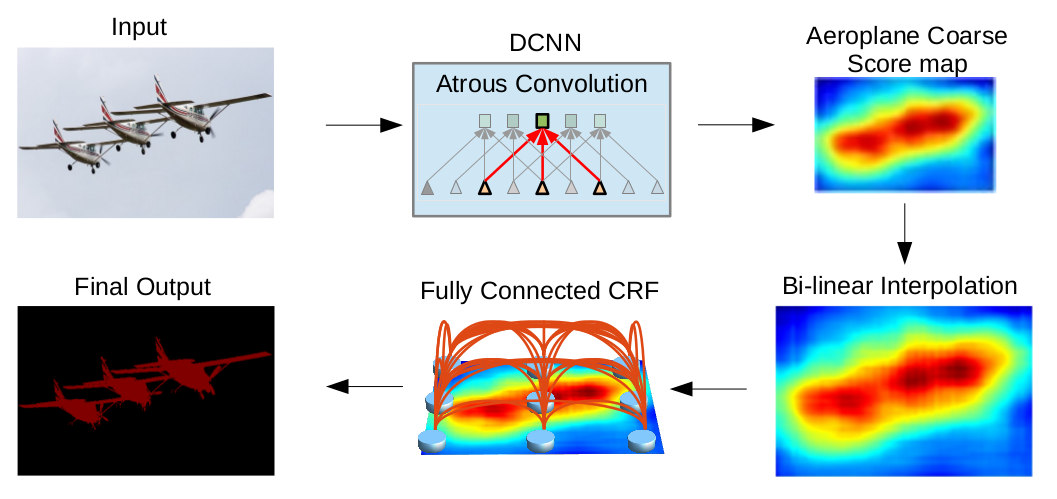
用于稠密特征提取和视野增大的多孔卷积
对于重复使用卷积和池化操作导致特征图分辨率丢失的问题,作者采用了一个叫做 atrous convolution 的卷积操作,这和 dilated convolution 思想是一样的,这里不再做详细介绍。
Atrous convolution 结合了传统的 downsampling,convolution 和 upsampling,得到的图像大小相同,但是特征明显清晰了很多, 如下图所示:
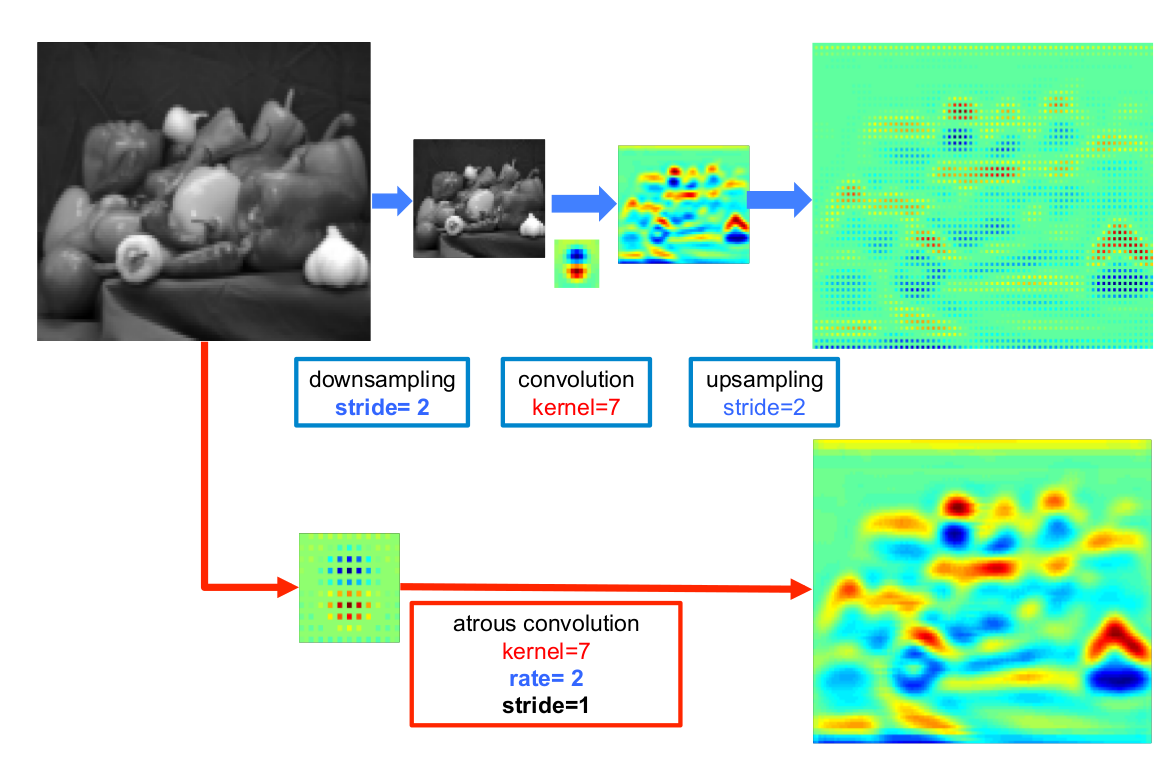
上图展示了 2D 算法操作的一个简单例子。上排:低分辨率输入特征地图的标准卷积稀疏特征提取;下排:高分辨率输入特征地图多孔卷积比例 r=2 的稠密特征提取。
用多孔空间金字塔池化的多尺度图像表示
对于第二个问题, 受 R-CNN 空间金字塔池化方法成功的启发,任意一个尺度上的区域都可以用单一尺度上重采样卷积特征进行精确有效地分类。论文使用多个不同采样率上的多个并行多孔卷积层,在每个采样率上提取特征然后再用单独的分支处理,融合生成最后的结果。如下图所示
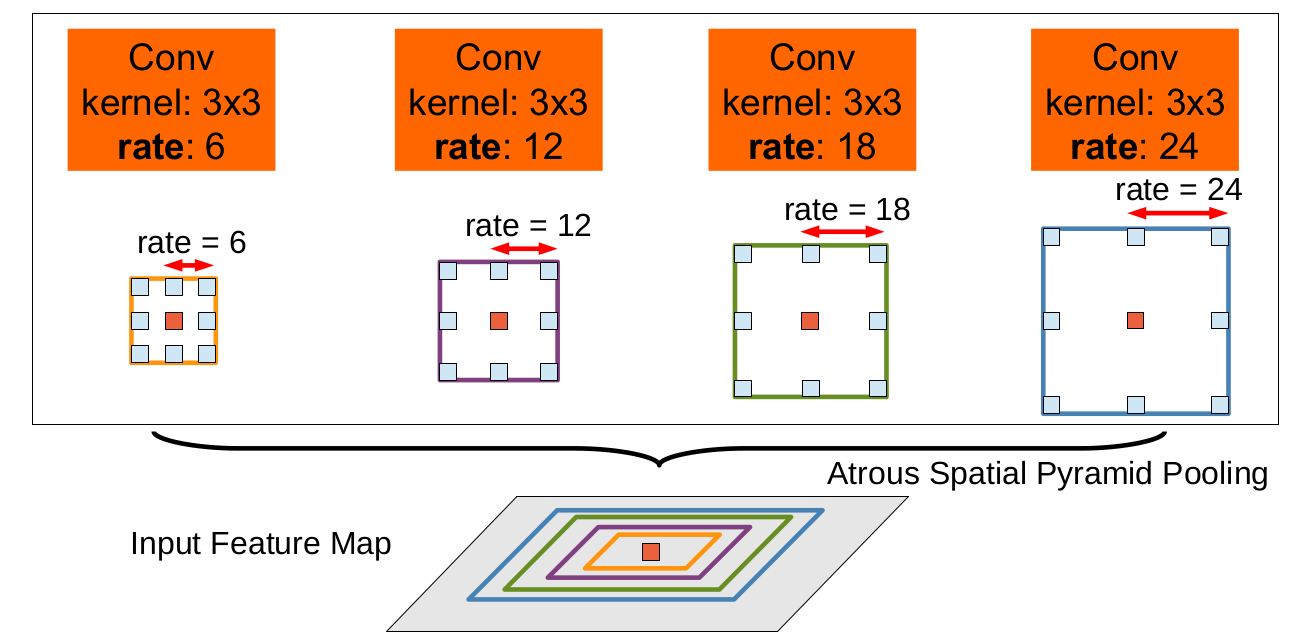
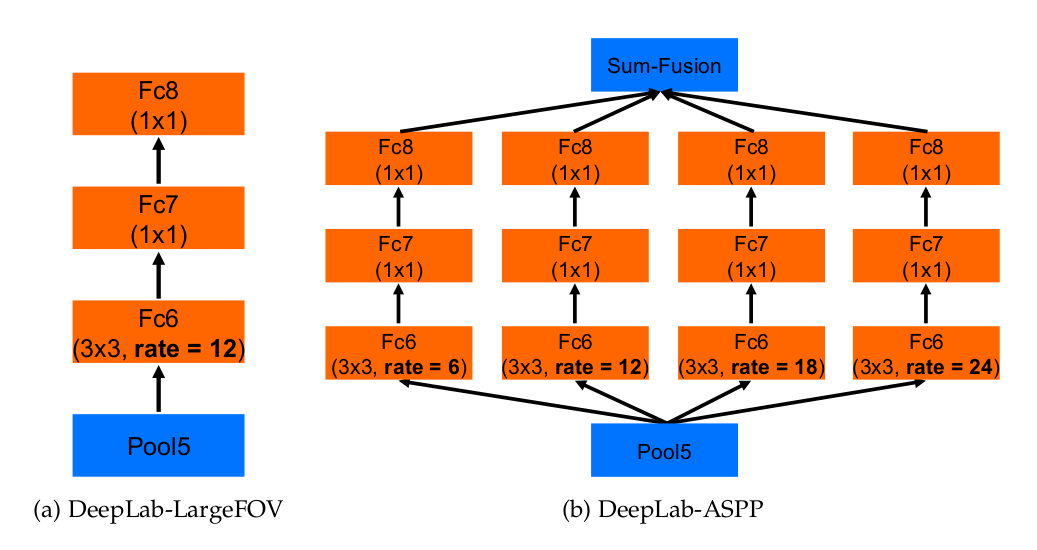
“多孔空间金字塔池化”(DeepLab-ASPP)方法可以泛化了 DeepLab-LargeFOV,如下图所示
用于精确边界恢复的全连接的条件随机场
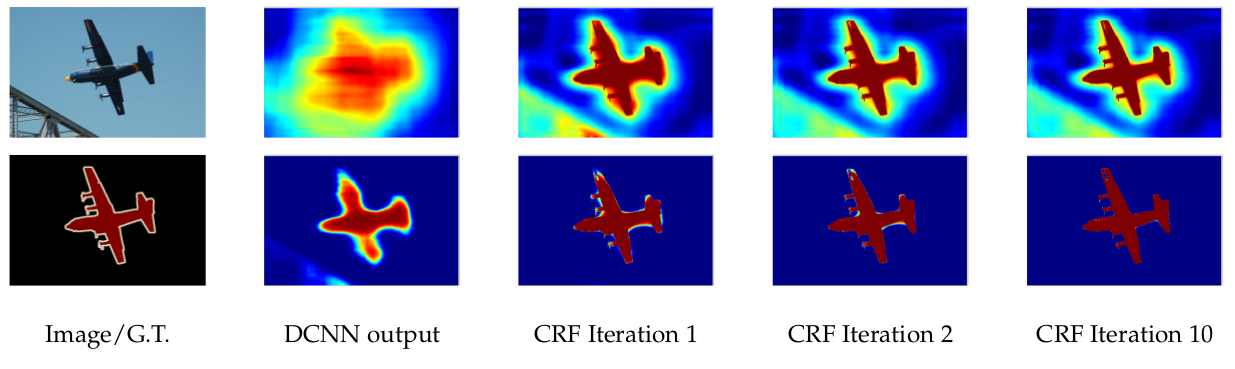
精确定位和分类性能在神经网络中往往需要权衡:带有最大池化层的更深的模型在分类任务上非常成功,但不变性增加,顶层结点的大感受野只能产生平滑响应,这就使得深度卷积神经网络得分地图可以预测是否有物体,以及物体出现的大致位置,但不能真正描绘它们的边界。
论文将深度卷积神经网络的识别能力和全连接条件随机场优化的定位精度耦合在一起,非常成功地处理定位挑战问题,生成了精确的语义分割结果。
传统方法中,条件随机场用于平滑带噪声的分割图。这些模型将邻近结点耦合,有利于将相同标记分配给空间上接近的像素,这些短程条件随机场主函数会清除构建在局部手动特征上层弱分类器的错误预测。与这些弱分类器相比,现代深度卷积神经网络架构生成的得分地图通常非常平滑,在这种情形下,用短程条件随机场结果可能不理想。我们的目标是要恢复详细的局部结构而不是平滑它,用局部条件随机场关联中的反差灵敏势,可以增强定位,但还是会漏掉细小结构,通常都需要处理离散优化问题。为了克服短程条件随机场的局限,论文使用了全连接随机场模型。
使用 CRF 结果如下:
总结
论文部分结果展示:

主要贡献:
- 采用了带孔/空洞卷积(atrous/dilated convolution)
- 提出了金字塔型的空洞池化(atrous spatial pyramid pooling,ASPP)
- 采用全连接的 CRF
RefineNet
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
Submitted on 20 Nov 2016
采用空洞/带孔卷积的方法也存在缺点。空洞卷积需要大量的高分辨率特征图,因此对计算量和内存的消耗都很大,这也限制方法无法应用于高分辨率的精细预测。例如 DeepLab 中分割结果图采用原始输入图像的 1/8 大小。
因此,论文提出一种编码器-解码器的架构。编码器是 ResNet-101 模块,解码器则是 RefineNet 模块,其连接/融合编码器的高分辨率特征和先前 RefineNet 块中的低分辨率特征。从网络结构来看,该工作是 U-Net 的一个变种,文章的主要贡献和创新在于 U-Net 折返向上的通路之中。
论文提出的网络模型可以分为两段对应于 U-Net 中向下(特征逐步降采样同时提取语义特征)和向上(逐步上采样特征恢复细节信息)两段通路。其中向下的通路以 ResNet 为基础。向上的通路使用了新提出的 RefineNet 作为基础,并作为本通路特征与 ResNet 中低层特征的融合器。一个基本的框架如下图 (c) 所示:
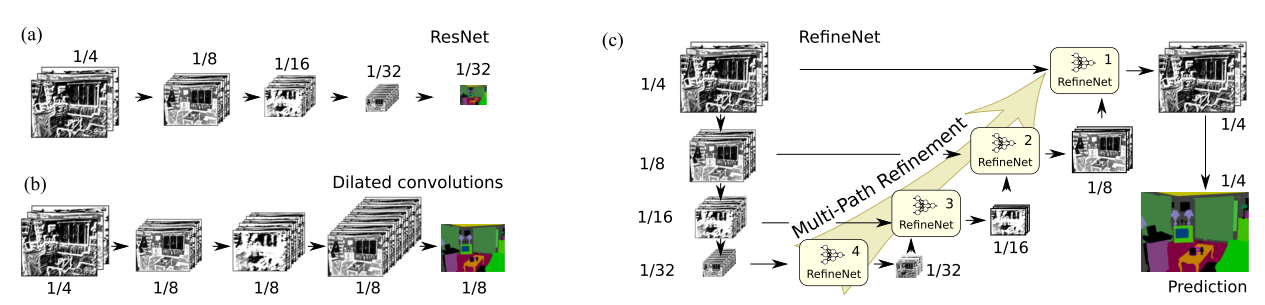
图a)代表的是标准的CNN结构
图b)代表的是带孔卷积dilated convolutions
图c)代表的是 RefineNet 的思路, 每一个小模块是一个 RefineNet, 融合了不同尺度下的 RefineNet 结果, 最终 upsample 到原图的 1/4 大小
RefineNet 细节
RefineNet 可以分为三个主要部分:
- 不同尺度(也可能只有一个输入尺度)的特征输入首先经过两个 Residual 模块的处理;
- 之后是不同尺寸的特征进行融合。当然如果只有一个输入尺度,该模块则可以省去。所有特征上采样至最大的输入尺寸,然后进行加和。上采样之前的卷积模块是为了调整不同特征的数值尺度;
- 最后是一个链式的 pooling 模块。其设计本意是使用侧支上一系列的 pooling 来获取背景信息(通常尺寸较大)。直连通路上的 ReLU 可以在不显著影响梯度流通的情况下提高后续 pooling 的性能,同时不让网络的训练对学习率很敏感。
最后再经过一个 Residual 模块即得 RefineNet 的输出。
如下图所示: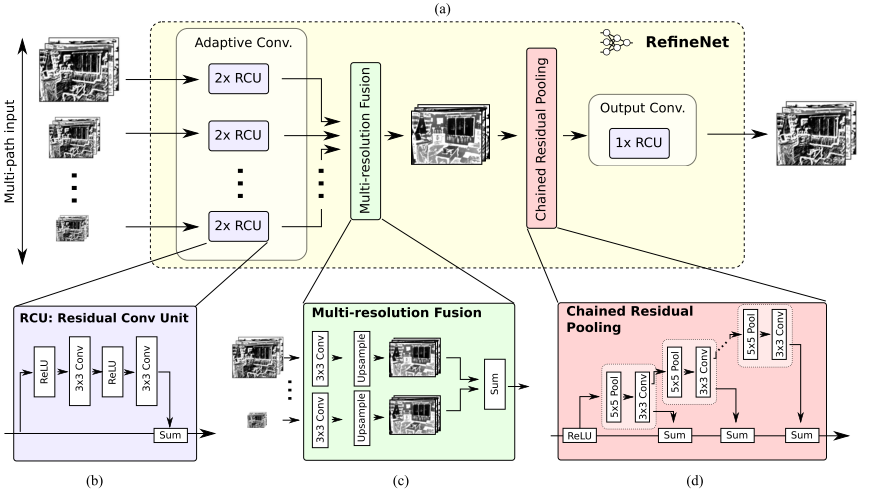
RefineNet 的一个特点是使用了较多的 residual connection。这样的好处不仅在于在 RefineNet 内部形成了 short-range 的连接,对训练有益。此外还与 ResNet 形成了 long-range 的连接,让梯度能够有效传送到整个网络中。作者认为这一点对于网络是很有好处的。
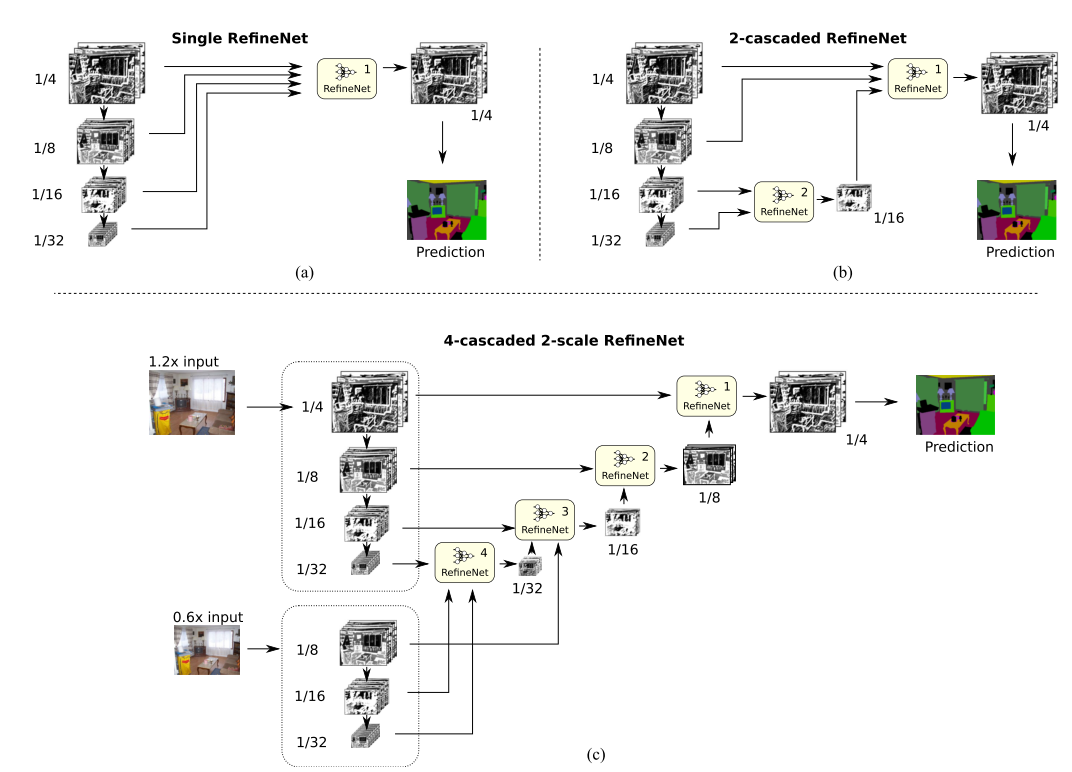
几种不同的 RefineNet 设计
主要贡献
- 编码器-解码器架构拥有精心设计的解码器模块
- 所有组件采用残差连接(residual connection)的设计
PSPNet
Pyramid Scene Parsing Network
Submitted on 4 Dec 2016
Large Kernel Matters
Large Kernel Matters — Improve Semantic Segmentation by Global Convolutional Network
Submitted on 8 Mar 2017
DeepLab v3
Rethinking Atrous Convolution for Semantic Image Segmentation
Submitted on 17 Jun 2017
参考文章
A 2017 Guide to Semantic Segmentation with Deep Learning
深度学习之图像分割-FCN
论文阅读理解 - Dilated Convolution
DeepLab: Semantic Image Segmentation
【总结】图像语义分割之FCN和CRF
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic